

| Neural Network Toolbox | |
ADALINE - An acronym for a linear neuron: ADAptive LINear Element.
adaption - A training method that proceeds through the specified sequence of inputs, calculating the output, error and network adjustment for each input vector in the sequence as the inputs are presented.
adaptive learning rate - A learning rate that is adjusted according to an algorithm during training to minimize training time.
adaptive filter - A network that contains delays and whose weights are adjusted after each new input vector is presented. The network "adapts" to changes in the input signal properties if such occur. This kind of filter is used in long distance telephone lines to cancel echoes.
architecture - A description of the number of the layers in a neural network, each layer's transfer function, the number of neurons per layer, and the connections between layers.
backpropagation learning rule - A learning rule in which weights and biases are adjusted by error-derivative (delta) vectors backpropagated through the network. Backpropagation is commonly applied to feedforward multilayer networks. Sometimes this rule is called the generalized delta rule.
backtracking search - Linear search routine that begins with a step multiplier of 1 and then backtracks until an acceptable reduction in the performance is obtained.
batch - A matrix of input (or target) vectors applied to the network "simultaneously." Changes to the network weights and biases are made just once for the entire set of vectors in the input matrix. (This term is being replaced by the more descriptive expression "concurrent vectors.")
batching - The process of presenting a set of input vectors for simultaneous calculation of a matrix of output vectors and/or new weights and biases.
Bayesian framework - Assumes that the weights and biases of the network are random variables with specified distributions.
BFGS quasi-Newton algorithm - A variation of Newton's optimization algorithm, in which an approximation of the Hessian matrix is obtained from gradients computed at each iteration of the algorithm.
bias - A neuron parameter that is summed with the neuron's weighted inputs and passed through the neuron's transfer function to generate the neuron's output.
bias vector - A column vector of bias values for a layer of neurons.
Brent's search - A linear search that is a hybrid combination of the golden section search and a quadratic interpolation.
Charalambous' search - A hybrid line search that uses a cubic interpolation, together with a type of sectioning.
cascade forward network - A layered network in which each layer only receives inputs from previous layers.
classification - An association of an input vector with a particular target vector.
competitive layer - A layer of neurons in which only the neuron with maximum net input has an output of 1 and all other neurons have an output of 0. Neurons compete with each other for the right to respond to a given input vector.
competitive learning - The unsupervised training of a competitive layer with the instar rule or Kohonen rule. Individual neurons learn to become feature detectors. After training, the layer categorizes input vectors among its neurons.
competitive transfer function - Accepts a net input vector for a layer and returns neuron outputs of 0 for all neurons except for the "winner," the neuron associated with the most positive element of the net input n.
concurrent input vectors - Name given to a matrix of input vectors that are to be presented to a network "simultaneously." All the vectors in the matrix will be used in making just one set of changes in the weights and biases.
conjugate gradient algorithm - In the conjugate gradient algorithms a search is performed along conjugate directions, which produces generally faster convergence than a search along the steepest descent directions.
connection - A one-way link between neurons in a network.
connection strength - The strength of a link between two neurons in a network. The strength, often called weight, determines the effect that one neuron has on another.
cycle - A single presentation of an input vector, calculation of output, and new weights and biases.
dead neurons - A competitive layer neuron that never won any competition during training and so has not become a useful feature detector. Dead neurons do not respond to any of the training vectors.
decision boundary - A line, determined by the weight and bias vectors, for which the net input n is zero.
delta rule - See the Widrow-Hoff learning rule.
delta vector - The delta vector for a layer is the derivative of a network's output error with respect to that layer's net input vector.
distance - The distance between neurons, calculated from their positions with a distance function.
distance function - A particular way of calculating distance, such as the Euclidean distance between two vectors.
early stopping - A technique based on dividing the data into three subsets. The first subset is the training set used for computing the gradient and updating the network weights and biases. The second subset is the validation set. When the validation error increases for a specified number of iterations, the training is stopped, and the weights and biases at the minimum of the validation error are returned. The third subset is the test set. It is used to verify the network design.
epoch - The presentation of the set of training (input and/or target) vectors to a network and the calculation of new weights and biases. Note that training vectors can be presented one at a time or all together in a batch.
error jumping - A sudden increase in a network's sum-squared error during training. This is often due to too large a learning rate.
error ratio - A training parameter used with adaptive learning rate and momentum training of backpropagation networks.
error vector - The difference between a network's output vector in response to an input vector and an associated target output vector.
feedback network - A network with connections from a layer's output to that layer's input. The feedback connection can be direct or pass through several layers.
feedforward network - A layered network in which each layer only receives inputs from previous layers.
Fletcher-Reeves update - A method developed by Fletcher and Reeves for computing a set of conjugate directions. These directions are used as search directions as part of a conjugate gradient optimization procedure.
function approximation - The task performed by a network trained to respond to inputs with an approximation of a desired function.
generalization - An attribute of a network whose output for a new input vector tends to be close to outputs for similar input vectors in its training set.
generalized regression network - Approximates a continuous function to an arbitrary accuracy, given a sufficient number of hidden neurons.
global minimum - The lowest value of a function over the entire range of its input parameters. Gradient descent methods adjust weights and biases in order to find the global minimum of error for a network.
golden section search - A linear search that does not require the calculation of the slope. The interval containing the minimum of the performance is subdivided at each iteration of the search, and one subdivision is eliminated at each iteration.
gradient descent - The process of making changes to weights and biases, where the changes are proportional to the derivatives of network error with respect to those weights and biases. This is done to minimize network error.
hard-limit transfer function - A transfer that maps inputs greater-than or equal-to 0 to 1, and all other values to 0.
Hebb learning rule - Historically the first proposed learning rule for neurons. Weights are adjusted proportional to the product of the outputs of pre- and post-weight neurons.
hidden layer - A layer of a network that is not connected to the network output. (For instance, the first layer of a two-layer feedforward network.)
home neuron - A neuron at the center of a neighborhood.
hybrid bisection-cubicsearch - A line search that combines bisection and cubic interpolation.
input layer - A layer of neurons receiving inputs directly from outside the network.
initialization - The process of setting the network weights and biases to their original values.
input space - The range of all possible input vectors.
input vector - A vector presented to the network.
input weights - The weights connecting network inputs to layers.
input weight vector - The row vector of weights going to a neuron.
Jacobian matrix - Contains the first derivatives of the network errors with respect to the weights and biases.
Kohonen learning rule - A learning rule that trains selected neuron's weight vectors to take on the values of the current input vector.
layer - A group of neurons having connections to the same inputs and sending outputs to the same destinations.
layer diagram - A network architecture figure showing the layers and the weight matrices connecting them. Each layer's transfer function is indicated with a symbol. Sizes of input, output, bias and weight matrices are shown. Individual neurons and connections are not shown. (See Chapter 2.)
layer weights - The weights connecting layers to other layers. Such weights need to have non-zero delays if they form a recurrent connection (i.e., a loop).
learning - The process by which weights and biases are adjusted to achieve some desired network behavior.
learning rate - A training parameter that controls the size of weight and bias changes during learning.
learning rules - Methods of deriving the next changes that might be made in a network OR a procedure for modifying the weights and biases of a network.
Levenberg-Marquardt - An algorithm that trains a neural network 10 to 100 faster than the usual gradient descent backpropagation method. It will always compute the approximate Hessian matrix, which has dimensions n-by-n.
line search function - Procedure for searching along a given search direction (line) to locate the minimum of the network performance.
linear transfer function - A transfer function that produces its input as its output.
link distance - The number of links, or steps, that must be taken to get to the neuron under consideration.
local minimum - The minimum of a function over a limited range of input values. A local minimum may not be the global minimum.
log-sigmoid transfer function - A squashing function of the form shown below that maps the input to the interval (0,1). (The toolbox function is logsig.)
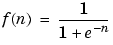
Manhattan distance - The Manhattan distance between two vectors x and y is calculated as:
maximum performance increase - The maximum amount by which the performance is allowed to increase in one iteration of the variable learning rate training algorithm.
maximum step size - The maximum step size allowed during a linear search. The magnitude of the weight vector is not allowed to increase by more than this maximum step size in one iteration of a training algorithm.
mean square error function - The performance function that calculates the average squared error between the network outputs a and the target outputs t.
momentum - A technique often used to make it less likely for a backpropagation networks to get caught in a shallow minima.
momentum constant - A training parameter that controls how much "momentum" is used.
mu parameter - The initial value for the scalar µ.
neighborhood - A group of neurons within a specified distance of a particular neuron. The neighborhood is specified by the indices for all of the neurons that lie within a radius 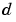 of the winning neuron
of the winning neuron 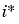 :
:
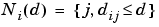
net input vector - The combination, in a layer, of all the layer's weighted input vectors with its bias.
neuron - The basic processing element of a neural network. Includes weights and bias, a summing junction and an output transfer function. Artificial neurons, such as those simulated and trained with this toolbox, are abstractions of biological neurons.
neuron diagram - A network architecture figure showing the neurons and the weights connecting them. Each neuron's transfer function is indicated with a symbol.
ordering phase - Period of training during which neuron weights are expected to order themselves in the input space consistent with the associated neuron positions.
output layer - A layer whose output is passed to the world outside the network.
output vector - The output of a neural network. Each element of the output vector is the output of a neuron.
output weight vector - The column vector of weights coming from a neuron or input. (See outstar learning rule.)
outstar learning rule - A learning rule that trains a neuron's (or input's) output weight vector to take on the values of the current output vector of the post-weight layer. Changes in the weights are proportional to the neuron's output.
overfitting - A case in which the error on the training set is driven to a very small value, but when new data is presented to the network, the error is large.
pass - Each traverse through all of the training input and target vectors.
pattern association - The task performed by a network trained to respond with the correct output vector for each presented input vector.
pattern recognition - The task performed by a network trained to respond when an input vector close to a learned vector is presented. The network "recognizes" the input as one of the original target vectors.
performance function - Commonly the mean squared error of the network outputs. However, the toolbox also considers other performance functions. Type nnets and look under performance functions.
perceptron - A single-layer network with a hard-limit transfer function. This network is often trained with the perceptron learning rule.
perceptron learning rule - A learning rule for training single-layer hard-limit networks. It is guaranteed to result in a perfectly functioning network in finite time, given that the network is capable of doing so.
performance - The behavior of a network.
Polak-Ribiére update - A method developed by Polak and Ribiére for computing a set of conjugate directions. These directions are used as search directions as part of a conjugate gradient optimization procedure.
positive linear transfer function - A transfer function that produces an output of zero for negative inputs and an output equal to the input for positive inputs.
postprocessing - Converts normalized outputs back into the same units that were used for the original targets.
Powell-Beale restarts - A method developed by Powell and Beale for computing a set of conjugate directions. These directions are used as search directions as part of a conjugate gradient optimization procedure. This procedure also periodically resets the search direction to the negative of the gradient.
preprocessing - Perform some transformation of the input or target data before it is presented to the neural network.
principal component analysis - Orthogonalize the components of network input vectors. This procedure can also reduce the dimension of the input vectors by eliminating redundant components.
quasi-Newton algorithm - Class of optimization algorithm based on Newton's method. An approximate Hessian matrix is computed at each iteration of the algorithm based on the gradients.
radial basis networks - A neural network that can be designed directly by fitting special response elements where they will do the most good.
radial basis transfer function - The transfer function for a radial basis neuron is:
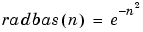
regularization - Involves modifying the performance function, which is normally chosen to be the sum of squares of the network errors on the training set, by adding some fraction of the squares of the network weights.
resilient backpropagation - A training algorithm that eliminates the harmful effect of having a small slope at the extreme ends of the sigmoid "squashing" transfer functions.
saturating linear transfer function - A function that is linear in the interval (-1,+1) and saturates outside this interval to -1 or +1. (The toolbox function is satlin.)
scaled conjugate gradient algorithm - Avoids the time consuming line search of the standard conjugate gradient algorithm.
sequential input vectors - A set of vectors that are to be presented to a network "one after the other." The network weights and biases are adjusted on the presentation of each input vector.
sigma parameter - Determines the change in weight for the calculation of the approximate Hessian matrix in the scaled conjugate gradient algorithm.
sigmoid - Monotonic S-shaped function mapping numbers in the interval (-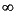 ,) to a finite interval such as (-1,+1) or (0,1).
,) to a finite interval such as (-1,+1) or (0,1).
simulation - Takes the network input p, and the network object net, and returns the network outputs a.
spread constant - The distance an input vector must be from a neuron's weight vector to produce an output of 0.5.
squashing function - A monotonic increasing function that takes input values between - and + and returns values in a finite interval.
star learning rule - A learning rule that trains a neuron's weight vector to take on the values of the current input vector. Changes in the weights are proportional to the neuron's output.
sum-squared error - The sum of squared differences between the network targets and actual outputs for a given input vector or set of vectors.
supervised learning - A learning process in which changes in a network's weights and biases are due to the intervention of any external teacher. The teacher typically provides output targets.
symmetric hard-limit transfer function - A transfer that maps inputs greater-than or equal-to 0 to +1, and all other values to -1.
symmetric saturating linear transfer function - Produces the input as its output as long as the input i in the range -1 to 1. Outside that range the output is -1 and +1 respectively.
tan-sigmoid transfer function - A squashing function of the form shown below that maps the input to the interval (-1,1). (The toolbox function is tansig.)
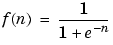
tapped delay line - A sequential set of delays with outputs available at each delay output.
target vector - The desired output vector for a given input vector.
test vectors - A set of input vectors (not used directly in training) that is used to test the trained network.
topology functions - Ways to arrange the neurons in a grid, box, hexagonal, or random topology.
training - A procedure whereby a network is adjusted to do a particular job. Commonly viewed as an "offline" job, as opposed to an adjustment made during each time interval as is done in adaptive training.
training vector - An input and/or target vector used to train a network.
transfer function - The function that maps a neuron's (or layer's) net output n to its actual output.
tuning phase - Period of SOFM training during which weights are expected to spread out relatively evenly over the input space while retaining their topological order found during the ordering phase.
underdetermined system - A system that has more variables than constraints.
unsupervised learning - A learning process in which changes in a network's weights and biases are not due to the intervention of any external teacher. Commonly changes are a function of the current network input vectors, output vectors, and previous weights and biases.
update - Make a change in weights and biases. The update can occur after presentation of a single input vector or after accumulating changes over several input vectors.
validation vectors - A set of input vectors (not used directly in training) that is used to monitor training progress so as to keep the network from overfitting.
weighted input vector - The result of applying a weight to a layer's input, whether it is a network input or the output of another layer.
weight function - Weight functions apply weights to an input to get weighted inputs as specified by a particular function.
weight matrix - A matrix containing connection strengths from a layer's inputs to its neurons. The element wi,j of a weight matrix W refers to the connection strength from input j to neuron i.
Widrow-Hoff learning rule - A learning rule used to trained single-layer linear networks. This rule is the predecessor of the backpropagation rule and is sometimes referred to as the delta rule.
| | vec2ind | Bibliography | |
© 1994-2005 The MathWorks, Inc.