| Neural Network Toolbox | |
Regularization
The first method for improving generalization is called regularization. This involves modifying the performance function, which is normally chosen to be the sum of squares of the network errors on the training set. The next subsection explains how the performance function can be modified, and the following subsection describes a routine that automatically sets the optimal performance function to achieve the best generalization.
Modified Performance Function
The typical performance function that is used for training feedforward neural networks is the mean sum of squares of the network errors.
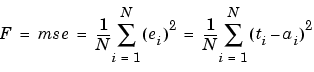
It is possible to improve generalization if we modify the performance function by adding a term that consists of the mean of the sum of squares of the network weights and biases
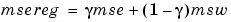
where 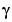 is the performance ratio, and
is the performance ratio, and
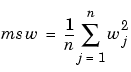
Using this performance function will cause the network to have smaller weights and biases, and this will force the network response to be smoother and less likely to overfit.
In the following code we reinitialize our previous network and retrain it using the BFGS algorithm with the regularized performance function. Here we set the performance ratio to 0.5, which gives equal weight to the mean square errors and the mean square weights.
p = [-1 -1 2 2;0 5 0 5]; t = [-1 -1 1 1]; net=newff(minmax(p),[3,1],{'tansig','purelin'},'trainbfg'); net.performFcn = 'msereg'; net.performParam.ratio = 0.5; net.trainParam.show = 5; net.trainParam.epochs = 300; net.trainParam.goal = 1e-5; [net,tr]=train(net,p,t);
The problem with regularization is that it is difficult to determine the optimum value for the performance ratio parameter. If we make this parameter too large, we may get overfitting. If the ratio is too small, the network will not adequately fit the training data. In the next section we describe a routine that automatically sets the regularization parameters.
Automated Regularization (trainbr)
It is desirable to determine the optimal regularization parameters in an automated fashion. One approach to this process is the Bayesian framework of David MacKay [MacK92]. In this framework, the weights and biases of the network are assumed to be random variables with specified distributions. The regularization parameters are related to the unknown variances associated with these distributions. We can then estimate these parameters using statistical techniques.
A detailed discussion of Bayesian regularization is beyond the scope of this users guide. A detailed discussion of the use of Bayesian regularization, in combination with Levenberg-Marquardt training, can be found in [FoHa97].
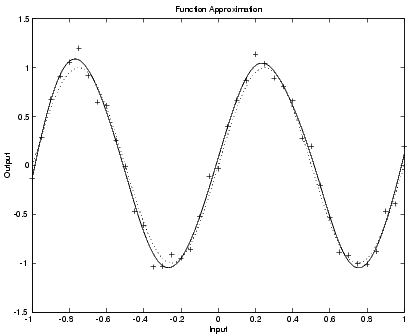
Bayesian regularization has been implemented in the function trainbr. The following code shows how we can train a 1-20-1 network using this function to approximate the noisy sine wave shown earlier in this section.
p = [-1:.05:1]; t = sin(2*pi*p)+0.1*randn(size(p)); net=newff(minmax(p),[20,1],{'tansig','purelin'},'trainbr'); net.trainParam.show = 10; net.trainParam.epochs = 50; randn('seed',192736547); net = init(net); [net,tr]=train(net,p,t); TRAINBR, Epoch 0/200, SSE 273.764/0, SSW 21460.5, Grad 2.96e+02/1.00e-10, #Par 6.10e+01/61 TRAINBR, Epoch 40/200, SSE 0.255652/0, SSW 1164.32, Grad 1.74e-02/1.00e-10, #Par 2.21e+01/61 TRAINBR, Epoch 80/200, SSE 0.317534/0, SSW 464.566, Grad 5.65e-02/1.00e-10, #Par 1.78e+01/61 TRAINBR, Epoch 120/200, SSE 0.379938/0, SSW 123.028, Grad 3.64e-01/1.00e-10, #Par 1.17e+01/61 TRAINBR, Epoch 160/200, SSE 0.380578/0, SSW 108.294, Grad 6.43e-02/1.00e-10, #Par 1.19e+01/61
One feature of this algorithm is that it provides a measure of how many network parameters (weights and biases) are being effectively used by the network. In this case, the final trained network uses approximately 12 parameters (indicated by #Par in the printout) out of the 61 total weights and biases in the 1-20-1 network. This effective number of parameters should remain approximately the same, no matter how large the total number of parameters in the network becomes. (This assumes that the network has been trained for a sufficient number of iterations to ensure convergence.)
The trainbr algorithm generally works best when the network inputs and targets are scaled so that they fall approximately in the range [-1,1]. That is the case for the test problem we have used. If your inputs and targets do not fall in this range, you can use the functions premnmx, or prestd, to perform the scaling, as described later in this chapter.
The following figure shows the response of the trained network. In contrast to the previous figure, in which a 1-20-1 network overfit the data, here we see that the network response is very close to the underlying sine function (dotted line), and, therefore, the network will generalize well to new inputs. We could have tried an even larger network, but the network response would never overfit the data. This eliminates the guesswork required in determining the optimum network size.
When using trainbr, it is important to let the algorithm run until the effective number of parameters has converged. The training may stop with the message "Maximum MU reached." This is typical, and is a good indication that the algorithm has truly converged. You can also tell that the algorithm has converged if the sum squared error (SSE) and sum squared weights (SSW) are relatively constant over several iterations. When this occurs you may want to push the "Stop Training" button in the training window.
| | Improving Generalization | Early Stopping | |
© 1994-2005 The MathWorks, Inc.