| Neural Network Toolbox | |
Sample Training Session
We have covered a number of different concepts in this chapter. At this point it might be useful to put some of these ideas together with an example of how a typical training session might go.
For this example, we are going to use data from a medical application [PuLu92]. We want to design an instrument that can determine serum cholesterol levels from measurements of spectral content of a blood sample. We have a total of 264 patients for which we have measurements of 21 wavelengths of the spectrum. For the same patients we also have measurements of hdl, ldl, and vldl cholesterol levels, based on serum separation. The first step is to load the data into the workspace and perform a principal component analysis.
Here we have conservatively retained those principal components which account for 99.9% of the variation in the data set. Let's check the size of the transformed data.
There was apparently significant redundancy in the data set, since the principal component analysis has reduced the size of the input vectors from 21 to 4.
The next step is to divide the data up into training, validation and test subsets. We will take one fourth of the data for the validation set, one fourth for the test set and one half for the training set. We pick the sets as equally spaced points throughout the original data.
iitst = 2:4:Q; iival = 4:4:Q; iitr = [1:4:Q 3:4:Q]; val.P = ptrans(:,iival); val.T = tn(:,iival); test.P = ptrans(:,iitst); test.T = tn(:,iitst); ptr = ptrans(:,iitr); ttr = tn(:,iitr);
We are now ready to create a network and train it. For this example, we will try a two-layer network, with tan-sigmoid transfer function in the hidden layer and a linear transfer function in the output layer. This is a useful structure for function approximation (or regression) problems. As an initial guess, we use five neurons in the hidden layer. The network should have three output neurons since there are three targets. We will use the Levenberg-Marquardt algorithm for training.
net = newff(minmax(ptr),[5 3],{'tansig' 'purelin'},'trainlm'); [net,tr]=train(net,ptr,ttr,[],[],val,test); TRAINLM, Epoch 0/100, MSE 3.11023/0, Gradient 804.959/1e-10 TRAINLM, Epoch 15/100, MSE 0.330295/0, Gradient 104.219/1e-10 TRAINLM, Validation stop.
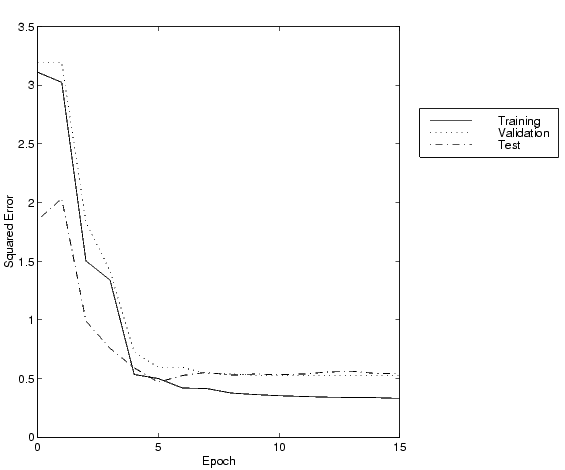
The training stopped after 15 iterations because the validation error increased. It is a useful diagnostic tool to plot the training, validation and test errors to check the progress of training. We can do that with the following commands.
plot(tr.epoch,tr.perf,tr.epoch,tr.vperf,tr.epoch,tr.tperf) legend('Training','Validation','Test',-1); ylabel('Squared Error'); xlabel('Epoch')
The result is shown in the following figure. The result here is reasonable, since the test set error and the validation set error have similar characteristics, and it doesn't appear that any significant overfitting has occurred.
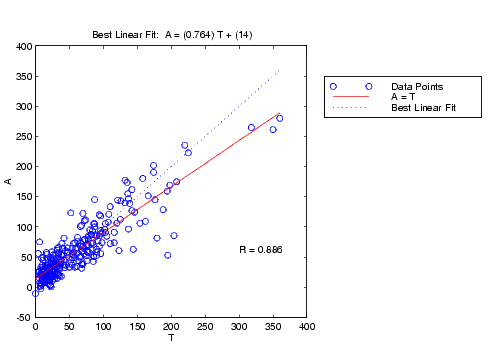
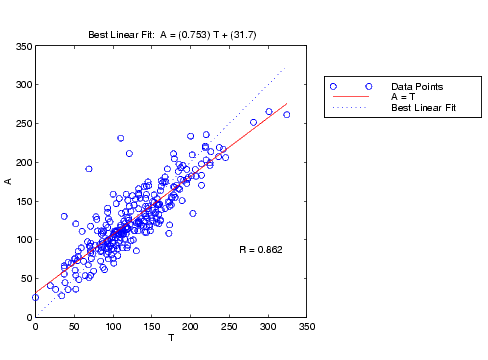
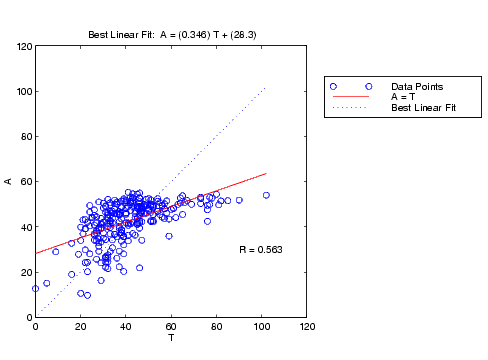
The next step is to perform some analysis of the network response. We will put the entire data set through the network (training, validation and test) and will perform a linear regression between the network outputs and the corresponding targets. First we need to unnormalize the network outputs.
an = sim(net,ptrans); a = poststd(an,meant,stdt); for i=1:3 figure(i) [m(i),b(i),r(i)] = postreg(a(i,:),t(i,:)); end
In this case, we have three outputs, so we perform three regressions. The results are shown in the following figures.
The first two outputs seem to track the targets reasonably well (this is a difficult problem), and the R-values are almost 0.9. The third output (vldl levels) is not well modeled. We probably need to work more on that problem. We might go on to try other network architectures (more hidden layer neurons), or to try Bayesian regularization instead of early stopping for our training technique. Of course there is also the possibility that vldl levels cannot be accurately computed based on the given spectral components.
The function demobp1 contains a Slide show demonstration of the sample training session. The function nnsample1 contains all of the commands that we used in this section. You can use it as a template for your own training sessions.
| | Post-Training Analysis (postreg) | Limitations and Cautions | |
© 1994-2005 The MathWorks, Inc.