| Neural Network Toolbox | |
Architecture
This section presents the architecture of the network that is most commonly used with the backpropagation algorithm - the multilayer feedforward network. The routines in the Neural Network Toolbox can be used to train more general networks; some of these will be briefly discussed in later chapters.
Neuron Model (tansig, logsig, purelin)
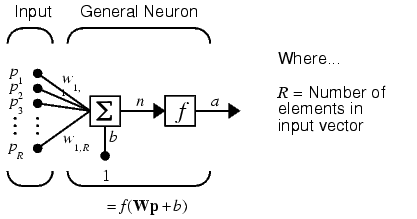
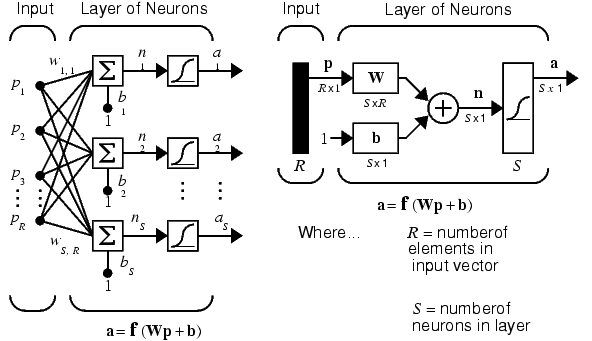
An elementary neuron with R inputs is shown below. Each input is weighted with an appropriate w. The sum of the weighted inputs and the bias forms the input to the transfer function f. Neurons may use any differentiable transfer function f to generate their output.
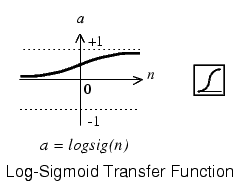
Multilayer networks often use the log-sigmoid transfer function logsig.
The function logsig generates outputs between 0 and 1 as the neuron's net input goes from negative to positive infinity.
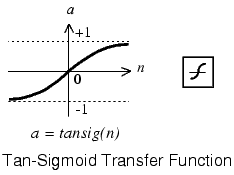
Alternatively, multilayer networks may use the tan-sigmoid transfer function tansig.
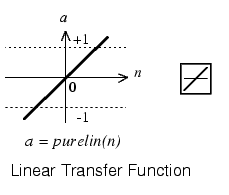
Occasionally, the linear transfer function purelin is used in backpropagation networks.
If the last layer of a multilayer network has sigmoid neurons, then the outputs of the network are limited to a small range. If linear output neurons are used the network outputs can take on any value.
In backpropagation it is important to be able to calculate the derivatives of any transfer functions used. Each of the transfer functions above, tansig, logsig, and purelin, have a corresponding derivative function: dtansig, dlogsig, and dpurelin. To get the name of a transfer function's associated derivative function, call the transfer function with the string 'deriv'.
The three transfer functions described here are the most commonly used transfer functions for backpropagation, but other differentiable transfer functions can be created and used with backpropagation if desired. See Advanced Topics.
Feedforward Network
A single-layer network of S logsig neurons having R inputs is shown below in full detail on the left and with a layer diagram on the right.
Feedforward networks often have one or more hidden layers of sigmoid neurons followed by an output layer of linear neurons. Multiple layers of neurons with nonlinear transfer functions allow the network to learn nonlinear and linear relationships between input and output vectors. The linear output layer lets the network produce values outside the range -1 to +1.
On the other hand, if you want to constrain the outputs of a network (such as between 0 and 1), then the output layer should use a sigmoid transfer function (such as logsig).
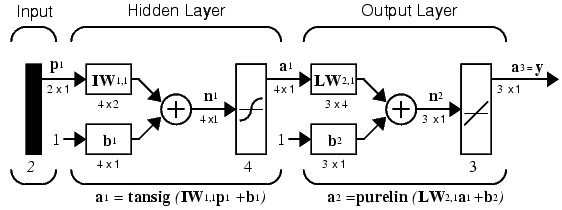
As noted in Neuron Model and Network Architectures, for multiple-layer networks we use the number of the layers to determine the superscript on the weight matrices. The appropriate notation is used in the two-layer tansig/purelin network shown next.
This network can be used as a general function approximator. It can approximate any function with a finite number of discontinuities, arbitrarily well, given sufficient neurons in the hidden layer.
Creating a Network (newff). The first step in training a feedforward network is to create the network object. The function newff creates a feedforward network. It requires four inputs and returns the network object. The first input is an R by 2 matrix of minimum and maximum values for each of the R elements of the input vector. The second input is an array containing the sizes of each layer. The third input is a cell array containing the names of the transfer functions to be used in each layer. The final input contains the name of the training function to be used.
For example, the following command creates a two-layer network. There is one input vector with two elements. The values for the first element of the input vector range between -1 and 2, the values of the second element of the input vector range between 0 and 5. There are three neurons in the first layer and one neuron in the second (output) layer. The transfer function in the first layer is tan-sigmoid, and the output layer transfer function is linear. The training function is traingd (which is described in a later section).
This command creates the network object and also initializes the weights and biases of the network; therefore the network is ready for training. There are times when you may want to reinitialize the weights, or to perform a custom initialization. The next section explains the details of the initialization process.
Initializing Weights (init). Before training a feedforward network, the weights and biases must be initialized. The newff command will automatically initialize the weights, but you may want to reinitialize them. This can be done with the command init. This function takes a network object as input and returns a network object with all weights and biases initialized. Here is how a network is initialized (or reinitialized):
For specifics on how the weights are initialized, see Advanced Topics.
| | Introduction | Simulation (sim) | |
© 1994-2005 The MathWorks, Inc.