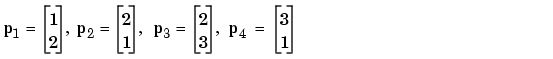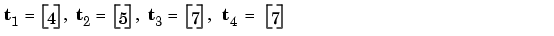| Neural Network Toolbox | |
Training Styles
In this section, we describe two different styles of training. In incremental training the weights and biases of the network are updated each time an input is presented to the network. In batch training the weights and biases are only updated after all of the inputs are presented.
Incremental Training (of Adaptive and Other Networks)
Incremental training can be applied to both static and dynamic networks, although it is more commonly used with dynamic networks, such as adaptive filters. In this section, we demonstrate how incremental training is performed on both static and dynamic networks.
Incremental Training with Static Networks
Consider again the static network we used for our first example. We want to train it incrementally, so that the weights and biases will be updated after each input is presented. In this case we use the function adapt, and we present the inputs and targets as sequences.
Suppose we want to train the network to create the linear function
Then for the previous inputs we used,
We first set up the network with zero initial weights and biases. We also set the learning rate to zero initially, to show the effect of the incremental training.
For incremental training we want to present the inputs and targets as sequences:
Recall from the earlier discussion that for a static network the simulation of the network produces the same outputs whether the inputs are presented as a matrix of concurrent vectors or as a cell array of sequential vectors. This is not true when training the network, however. When using the adapt function, if the inputs are presented as a cell array of sequential vectors, then the weights are updated as each input is presented (incremental mode). As we see in the next section, if the inputs are presented as a matrix of concurrent vectors, then the weights are updated only after all inputs are presented (batch mode).
We are now ready to train the network incrementally.
The network outputs will remain zero, since the learning rate is zero, and the weights are not updated. The errors will be equal to the targets:
If we now set the learning rate to 0.1 we can see how the network is adjusted as each input is presented:
net.inputWeights{1,1}.learnParam.lr=0.1; net.biases{1,1}.learnParam.lr=0.1; [net,a,e,pf] = adapt(net,P,T); a = [0] [2] [6.0] [5.8] e = [4] [3] [1.0] [1.2]
The first output is the same as it was with zero learning rate, since no update is made until the first input is presented. The second output is different, since the weights have been updated. The weights continue to be modified as each error is computed. If the network is capable and the learning rate is set correctly, the error will eventually be driven to zero.
Incremental Training with Dynamic Networks
We can also train dynamic networks incrementally. In fact, this would be the most common situation. Let's take the linear network with one delay at the input that we used in a previous example. We initialize the weights to zero and set the learning rate to 0.1.
To train this network incrementally we present the inputs and targets as elements of cell arrays.
Here we attempt to train the network to sum the current and previous inputs to create the current output. This is the same input sequence we used in the previous example of using sim, except that we assign the first term in the sequence as the initial condition for the delay. We now can sequentially train the network using adapt.
The first output is zero, since the weights have not yet been updated. The weights change at each subsequent time step.
| | Simulation with Concurrent Inputs in a Dynamic Network | Batch Training | |
© 1994-2005 The MathWorks, Inc.
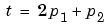 .
.