

| Neural Network Toolbox | |
Network Architecture
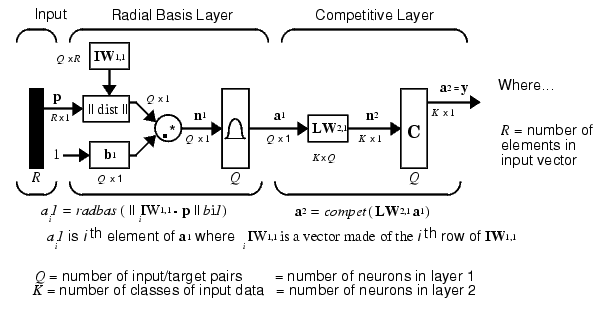
It is assumed that there are Q input vector/target vector pairs. Each target vector has K elements. One of these element is 1 and the rest is 0. Thus, each input vector is associated with one of K classes.
The first-layer input weights, IW1,1 (net.IW{1,1}) are set to the transpose of the matrix formed from the Q training pairs, P'. When an input is presented the ||dist|| box produces a vector whose elements indicate how close the input is to the vectors of the training set. These elements are multiplied, element by element, by the bias and sent the radbas transfer function. An input vector close to a training vector is represented by a number close to 1 in the output vector a1. If an input is close to several training vectors of a single class, it is represented by several elements of a1 that are close to 1.
The second-layer weights, LW1,2 (net.LW{2,1}), are set to the matrix T of target vectors. Each vector has a 1 only in the row associated with that particular class of input, and 0's elsewhere. (A function ind2vec is used to create the proper vectors.) The multiplication Ta1 sums the elements of a1 due to each of the K input classes. Finally, the second-layer transfer function, compete, produces a 1 corresponding to the largest element of n2, and 0's elsewhere. Thus, the network has classified the input vector into a specific one of K classes because that class had the maximum probability of being correct.
| | Probabilistic Neural Networks | Design (newpnn) | |
© 1994-2005 The MathWorks, Inc.