| Neural Network Toolbox | |
Training (learnsom)
Learning in a self-organizing feature map occurs for one vector at a time, independent of whether the network is trained directly (trainr) or whether it is trained adaptively (trains). In either case, learnsom is the self-organizing map weight learning function.
First the network identifies the winning neuron. Then the weights of the winning neuron, and the other neurons in its neighborhood, are moved closer to the input vector at each learning step using the self-organizing map learning function learnsom. The winning neuron's weights are altered proportional to the learning rate. The weights of neurons in its neighborhood are altered proportional to half the learning rate. The learning rate and the neighborhood distance used to determine which neurons are in the winning neuron's neighborhood are altered during training through two phases.
Phase 1: Ordering Phase
This phase lasts for the given number of steps. The neighborhood distance starts as the maximum distance between two neurons, and decreases to the tuning neighborhood distance. The learning rate starts at the ordering-phase learning rate and decreases until it reaches the tuning-phase learning rate. As the neighborhood distance and learning rate decrease over this phase, the neurons of the network typically order themselves in the input space with the same topology in which they are ordered physically.
Phase 2: Tuning Phase
This phase lasts for the rest of training or adaption. The neighborhood distance stays at the tuning neighborhood distance, (which should include only close neighbors (i.e., typically 1.0). The learning rate continues to decrease from the tuning phase learning rate, but very slowly. The small neighborhood and slowly decreasing learning rate fine tune the network, while keeping the ordering learned in the previous phase stable. The number of epochs for the tuning part of training (or time steps for adaption) should be much larger than the number of steps in the ordering phase, because the tuning phase usually takes much longer.
Now let us take a look at some of the specific values commonly used in these networks.
Learning occurs according to the learnsom learning parameter, shown here with its default value.
LP.order_lr |
|
Ordering-phase learning rate. |
LP.order_steps |
|
Ordering-phase steps. |
LP.tune_lr |
|
Tuning-phase learning rate. |
LP.tune_nd |
|
Tuning-phase neighborhood distance. |
learnsom calculates the weight change dW for a given neuron from the neuron's input P, activation A2, and learning rate LR:
where the activation A2 is found from the layer output A and neuron distances D and the current neighborhood size ND:
The learning rate LR and neighborhood size NS are altered through two phases: an ordering phase, and a tuning phase.
The ordering phase lasts as many steps as LP.order_steps. During this phase, LR is adjusted from LP.order_lr down to LP.tune_lr, and ND is adjusted from the maximum neuron distance down to 1. It is during this phase that neuron weights are expected to order themselves in the input space consistent with the associated neuron positions.
During the tuning phase LR decreases slowly from LP.tune_lr and ND is always set to LP.tune_nd. During this phase, the weights are expected to spread out relatively evenly over the input space while retaining their topological order found during the ordering phase.
Thus, the neuron's weight vectors initially take large steps all together toward the area of input space where input vectors are occurring. Then as the neighborhood size decreases to 1, the map tends to order itself topologically over the presented input vectors. Once the neighborhood size is 1, the network should be fairly well ordered and the learning rate is slowly decreased over a longer period to give the neurons time to spread out evenly across the input vectors.
As with competitive layers, the neurons of a self-organizing map will order themselves with approximately equal distances between them if input vectors appear with even probability throughout a section of the input space. Also, if input vectors occur with varying frequency throughout the input space, the feature map layer tends to allocate neurons to an area in proportion to the frequency of input vectors there.
Thus, feature maps, while learning to categorize their input, also learn both the topology and distribution of their input.
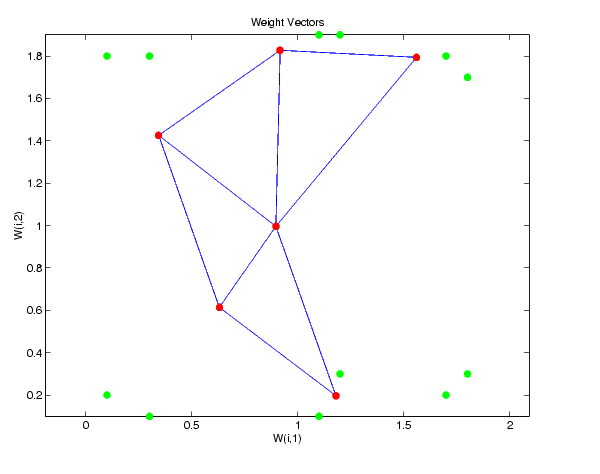
We can train the network for 1000 epochs with
This training produces the following plot.
We can see that the neurons have started to move toward the various training groups. Additional training is required to get the neurons closer to the various groups.
As noted previously, self-organizing maps differ from conventional competitive learning in terms of which neurons get their weights updated. Instead of updating only the winner, feature maps update the weights of the winner and its neighbors. The result is that neighboring neurons tend to have similar weight vectors and to be responsive to similar input vectors.
| | Creating a Self-Organizing MAP Neural Network (newsom) | Examples | |
© 1994-2005 The MathWorks, Inc.